We asked AI to assess quotes. It confidently made things up.
Mariano Carpentier
April 13, 2018
/
The hug of death, also known as 'Slashdot Effect' (4) is caused when someone posts a link to a website, for example, the press, saying "Hey everyone, look at this website!" and everyone does. This puts so much traffic on the site in question's servers that they get overloaded and crash, causing the site to be inaccessible until the amount of traffic slows down.
In this document I will explain how to setup pod auto-scaling as per Kubernetes 1.7.
First we need to setup the cpu requests. This is due to the autoscaling algorithm using the cpu requests to decide when to scale. For example if we decide to scale when we hit 50% of the cpu, that 50% will be decided towards the requested cpu and not actually a full cpu unit as per the 'top' command in bash (Linux).
In the snippet below I'm setting up a cpu request limit. On top of it I'm also setting up the cpu limits and memory request and limits. Cpu and memory requests provides Kubernetes enough information to know how many pods can fit on each node. Limits are passed to the Docker engine which in turn uses Cgroups to control the resource limits of each container.
This is the detail of the deployment yaml file that defines a pod and its limits.
- name: filebeat
image: komljen/filebeat
resources:
requests:
memory: "256M"
cpu: "0.02"
limits:
memory: "0.5Gi"
cpu: "0.2"
An alternative to individual limits is to create a Limit Range object.
A Limit Range provides default values within a namespace. Any particular container within a pod definition can overwrite the limit range values. One clarification though, in my test as per Kubernetes 1.7 the limit range values would not be picked up by the auto-scaler even after recreating the deployment so make sure that he kubectl get hpa returns something different than 'unknown' in order to check the limit is properly setup.
In any case, this is how it looks like: limitrange.yaml content
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-mem-limit-range
spec:
limits:
- default:
cpu: 0.5
memory: "0.5Gi"
defaultRequest:
cpu: 0.05
memory: "256M"
type: Container
Once you setup the cpu request, you are ready to setup autoscaling. But before, you need to decide how much cpu your pods should consume in order to trigger a scale order (cpu target value) Also you need to setup the maximum and minimum limits for your pods to scale up or down. Unfortunately you can't scale to infinite but surely to a very large number of pods.
The autoscaling algorithm will increase pods faster than it decreases them. This is to avoid noise and given that there is generally less rush increasing capacity rather than decreasing it.
Quoting the documentation (#2): "Starting and stopping pods may introduce noise to the metric (for instance, starting may temporarily increase CPU). So, after each action, the autoscaler should wait some time for reliable data. Scale-up can only happen if there was no rescaling within the last 3 minutes. Scale-down will wait for 5 minutes from the last rescaling."
We apply our autoscaling policy:
kubectl autoscale deployment file-beat --cpu-percent=50 --min=1 --max=5
In this case we are specifying to scale the file-beat deployment once the cpu load hits 50% of the cpu requested and up to 5 pods.
In order for this to work, make sure to specify a cpu target in all the containers within your deployment. To verify this, just run:
adrian@adrian-ubuntu:~$ kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE myapp Deployment/myapp/ 50% 1 5 1 6h app2 Deployment/app2 0% / 50% 1 5 1 5h
In the example above myapp doesn't have cpu target defined properly while app2 does. Therefore we can get autoscaling to properlt work for app2.
To simulate load within a pod you can run:
fulload() { dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null |dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null | dd if=/dev/zero of=/dev/null & }; fulload; read; killall dd
Other commands to help you out:
#to verify number of pods kubectl get pods -n dev |grep app #to get status updates from the auto-scaler k get hpa app2 -o yaml
Theory sounds good, but how does this actually works?
In the pictures below I'm running a demo using the commands above to show how to automatically scale based on load.
This picture show that my deployment only has one pod due to a very low activity: 0%
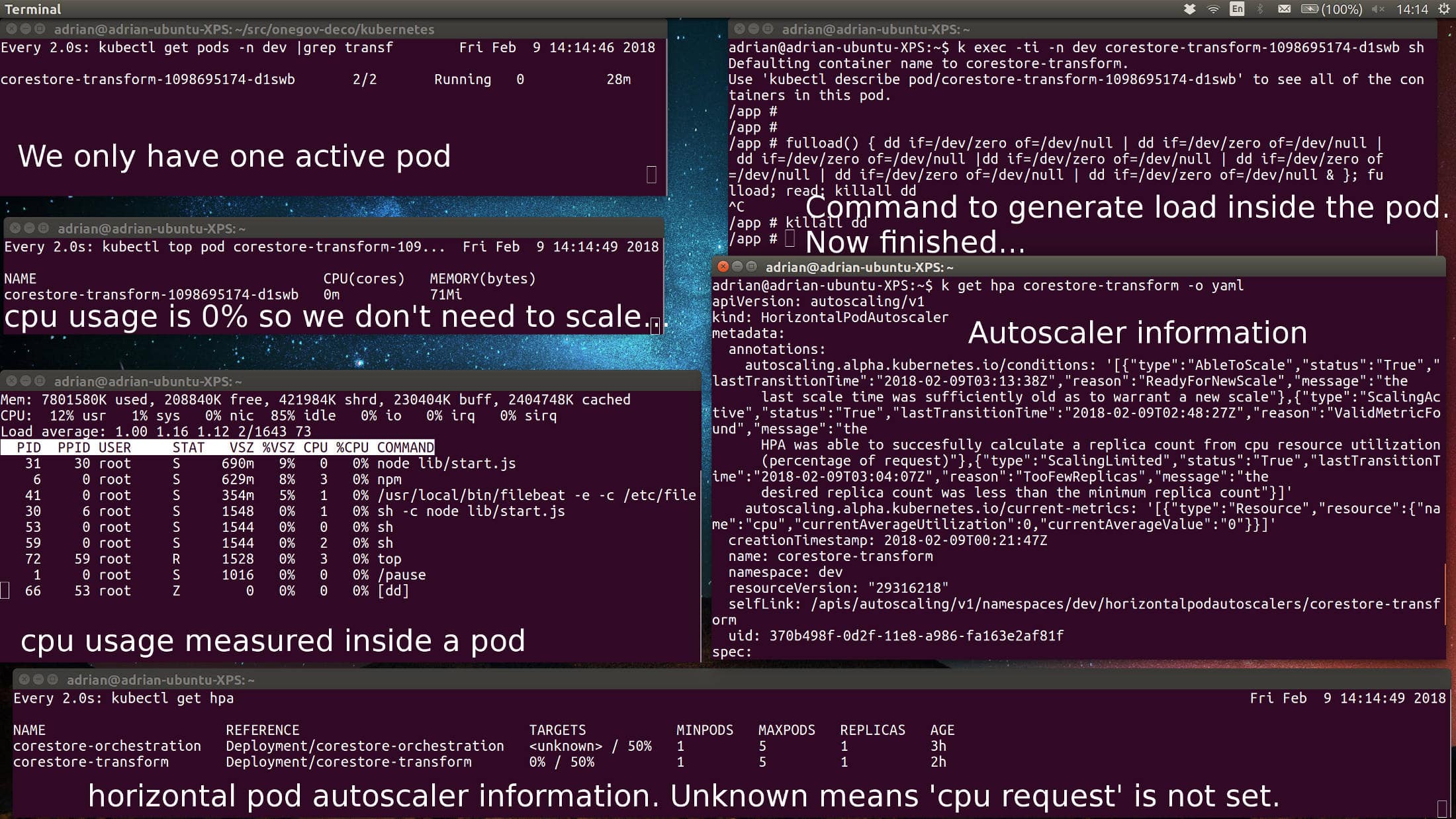
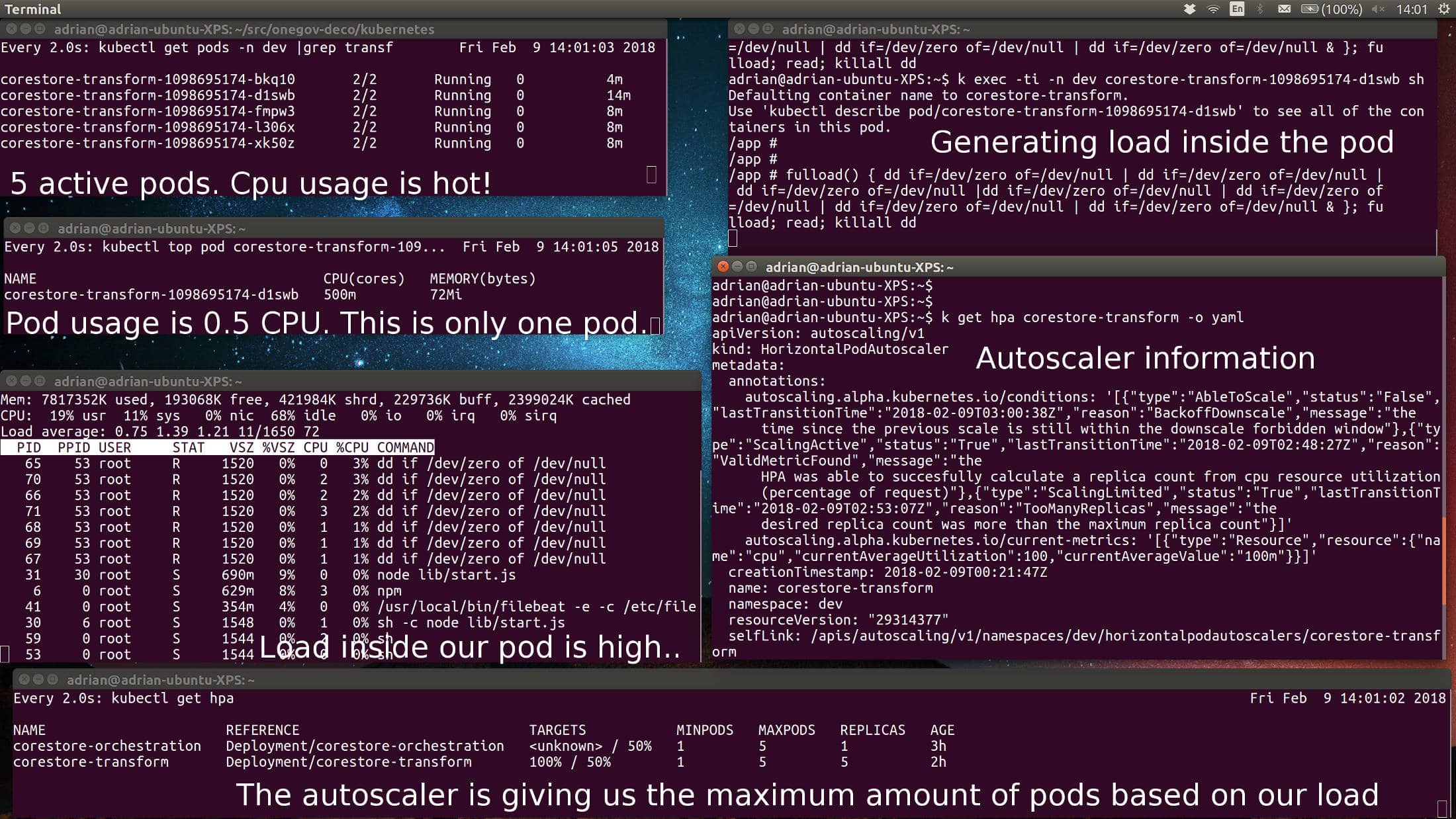
Now we are heating this up. Running some cpu intensive scripts will increase the load and cause the auto-scaler to start five pods. In reality, an increase on user activity would also increase cpu which would cause the hpa (horizontal pod autoscaler) to increase the amount of pods.

Mariano Carpentier
Behrouz Hassanbeygi

Behrouz Hassanbeygi

Behrouz Hassanbeygi

Behrouz Hassanbeygi
Felix Schmitz
Address
Level 8
11-17 York Street
Sydney NSW 2000
Phone Number
+61 2 8294 8067
Email
[email protected]
By Mariano Carpentier
By Behrouz Hassanbeygi
© 2017-2026 Darumatic Pty Ltd. All Rights Reserved.


