We asked AI to assess quotes. It confidently made things up.
Mariano Carpentier
Aug. 18, 2025
/
Kubernetes is a modular platform that, by default, supports ephemeral storage—meaning data disappears when a pod is destroyed. To extend its functionality and manage persistent data, we use the Container Storage Interface (CSI). The CSI acts as a standard API that allows Kubernetes to connect to a wide array of storage systems.
The process is straightforward:
PersistentVolumeClaim (PVC).PersistentVolume (PV) that satisfies the claim's requirements.For more information on creating PVCs and PVs, please read this article.
While the process is standardised, the key difference lies in the underlying storage provider, defined by a StorageClass. This choice, whether it's Ceph (managed by Rook), Portworx, Longhorn, or another solution, determines how your data is managed.
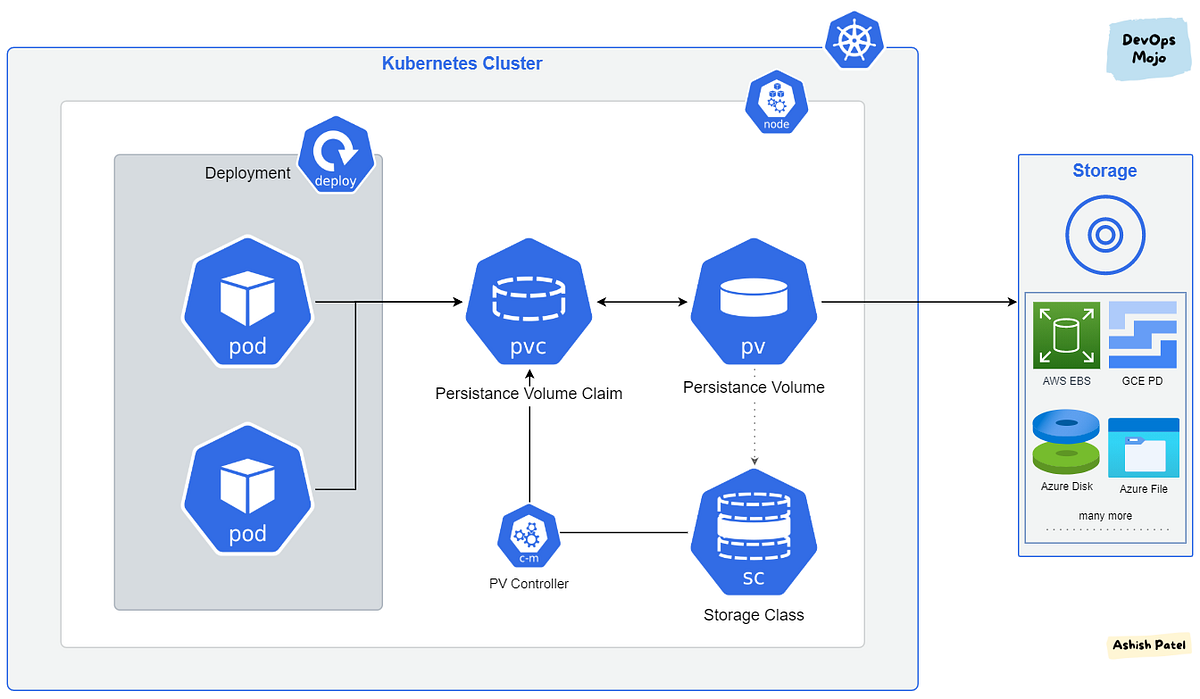
Unlike traditional virtual machine platforms where compute and storage often lived on the same machine, container orchestration aims for a more flexible "desired state." If we lose a node, we need the ability for workloads to quickly restart on another node and reconnect to their data seamlessly.
The core idea is that if a node fails, Kubernetes can reschedule the pods to a healthy node, which then attaches the same storage volume, ensuring data continuity and minimal downtime. This concept of remote, persistent storage serves several critical purposes:
Imagine you're running a high-availability WordPress site. This setup has two distinct data requirements:
For the database, the common solution is ReadWriteOnce (RWO) storage. Each MariaDB instance gets its own dedicated block volume that cannot be attached to other pods simultaneously, ensuring data integrity.
For the static wp-content files, we need storage that can be accessed by multiple pods at the same time. This is achieved with ReadWriteMany (RWX) storage, which functions like a shared network drive. Because of the complexities of managing a distributed file system, RWX volumes typically have higher latency and lower performance than their RWO counterparts.
A more modern alternative for shared files is to use an S3-compatible object store. Instead of mounting a shared directory, the application uses an S3 API to store and retrieve files. This approach simplifies the architecture and can be implemented on-premises using a MinIO cluster backed by high-performance RWO block storage.
The Kubernetes storage ecosystem is vast, with options ranging from open-source community projects to powerful proprietary platforms. Choosing the right one requires carefully balancing your organisation's technical needs, operational expertise, and budget.
Below, we compare four of the most popular solutions: Ceph (via Rook), Portworx, Longhorn, and OpenEBS.
This table outlines the core features supported by each solution.
| Feature | Ceph | Portworx | Longhorn | OpenEBS |
|---|---|---|---|---|
| S3 Object Storage | ✅ Yes (Native) | ❌ No (Backup Target Only) | ❌ No (Backup Target Only) | ❌ No (Integrates with MinIO) |
| Block Storage (RWO) | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| Shared File System (RWX) | ✅ Yes (Native) | ✅ Yes (Native) | ✅ Yes (Via NFS) | ✅ Yes (Via NFS) |
| Online Volume Resize | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| CSI Snapshots | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
This table provides a high-level overview to help guide your decision based on your team's expertise, budget, and technical requirements.
| Aspect | Ceph | Portworx | Longhorn | OpenEBS |
|---|---|---|---|---|
| License & Model | 📜 Open-Source | 🔒 Proprietary | 📜 Open-Source | 📜 Open-Source |
| ✅ Pros | • Unified Storage (Block, File, Object) • Massively Scalable • Highly Resilient & Mature |
• High Performance • Rich Enterprise Features (DR, Encryption) • Excellent Support & Simple Operations |
• Extremely Simple to Install & Manage • Lightweight & Low Overhead • Built-in Backup to S3/NFS |
• Truly Kubernetes-Native • Flexible (Pluggable Engines) • Granular Control |
| ❌ Cons | • High Complexity & Overhead • Difficult Performance Tuning |
• Expensive • Vendor Lock-in • Not Open-Source |
• Lower Performance for I/O-intensive Workloads • Higher Replication Overhead |
• "Paradox of Choice" with Many storage Engines • Varying Engine Maturity & Stability |
| 🎯 Ideal Use Case | Large-scale private clouds needing a unified platform with a dedicated ops team. | Mission-critical enterprise apps demanding the highest performance and support. | Dev/test, edge, and small-to-medium clusters where simplicity is key. | Environments that value flexibility and tailoring storage to specific workloads. |
| ⚙️ Implementation Complexity | High | Medium | Low | Low to Medium |
Finally, let's look at performance. The following benchmark results (sourced from an independent analysis ) highlight how these solutions stack up under various workloads. The top performer for each metric (Read and Write) is in bold.
| Product | Random Read / Write (IOPS) | Bandwidth Read / Write (MiB/s) | Avg. Latency Read / Write (µs) | Sequential Read / Write (MiB/s) | Mixed Random Read / Write (IOPS) |
|---|---|---|---|---|---|
| Portworx | 58,100 / 18,100 | 1282 / 257 | 137.85 / 256.42 | 1493 / 281 | 13,200 / 4,370 |
| StorageOS | 37,700 / 7,832 | 443 / 31.2 | 209.55 / 559.49 | 453 / 107 | 19,100 / 6,664 |
| Robin | 7,496 / 32,700 | 29.5 / 273 | 1119.50 / 786.46 | 54.6 / 270 | 7,458 / 2,483 |
| Rancher Longhorn | 7,028 / 4,032 | 302 / 204 | 1068.23 / 1303.46 | 358 / 236 | 4,826 / 1,614 |
| Rook (Ceph) | 4,262 / 3,523 | 225 / 141 | 1247.22 / 2229.20 | 245 / 168 | 3,047 / 1,021 |
| OpenEBS (cStor) | 2,475 / 2,893 | 21.9 / 52.2 | 2137.88 / 1861.59 | 6.3 / 54.2 | 2,786 / 943 |
Disclaimer: Performance benchmarks are highly dependent on the specific hardware, network infrastructure, and test configuration used. These results represent a single snapshot and may vary significantly in different environments.
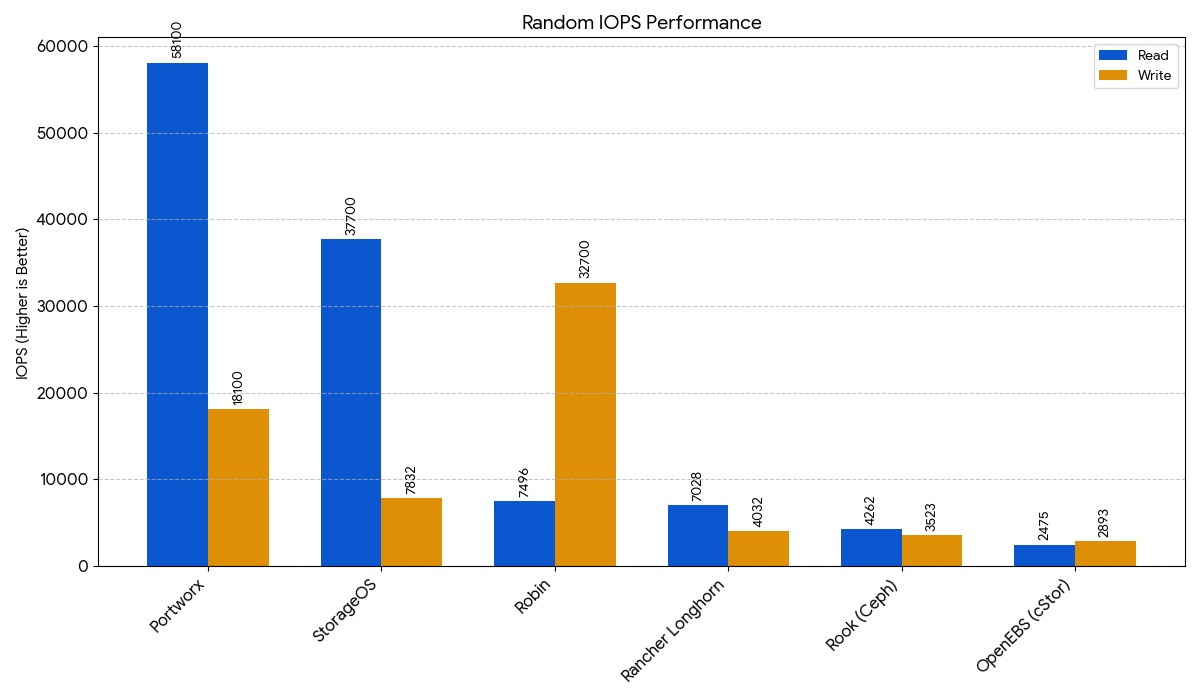
This chart shows the number of random read and write operations per second. Higher is better, as higher values indicate better performance for quickly accessing random data points, which is crucial for database workloads.
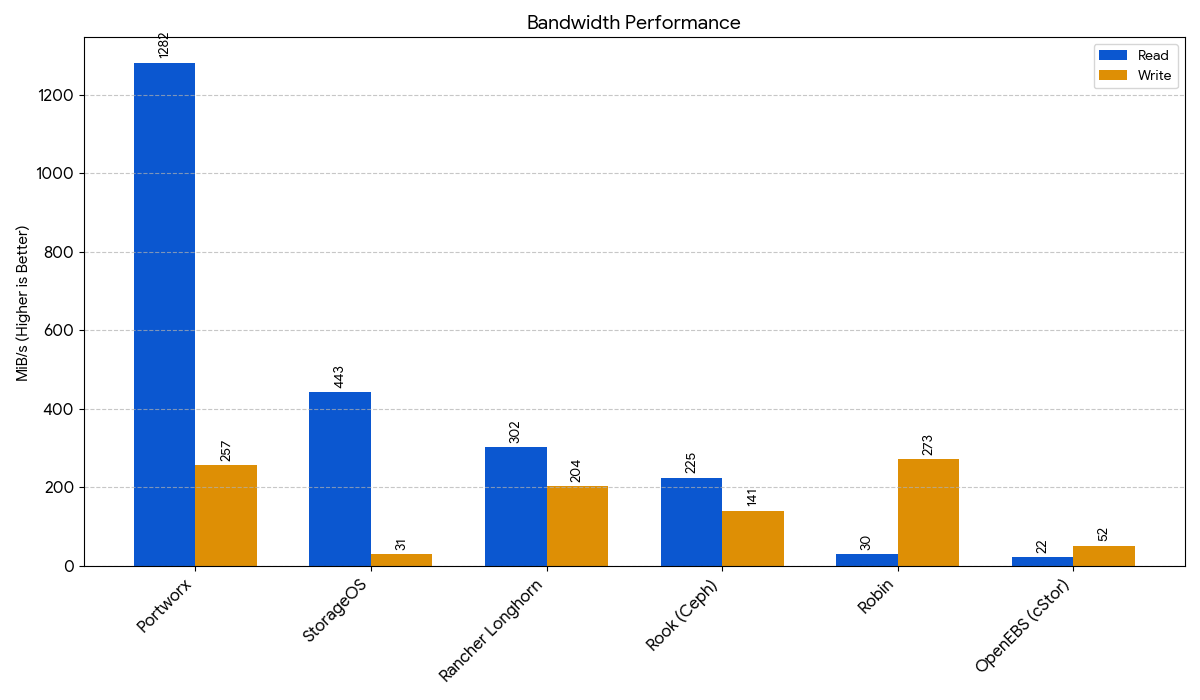
This chart displays the throughput for sustained read and write operations in megabytes per second (MiB/s). Higher is better, as more bandwidth is ideal for applications that move large files.
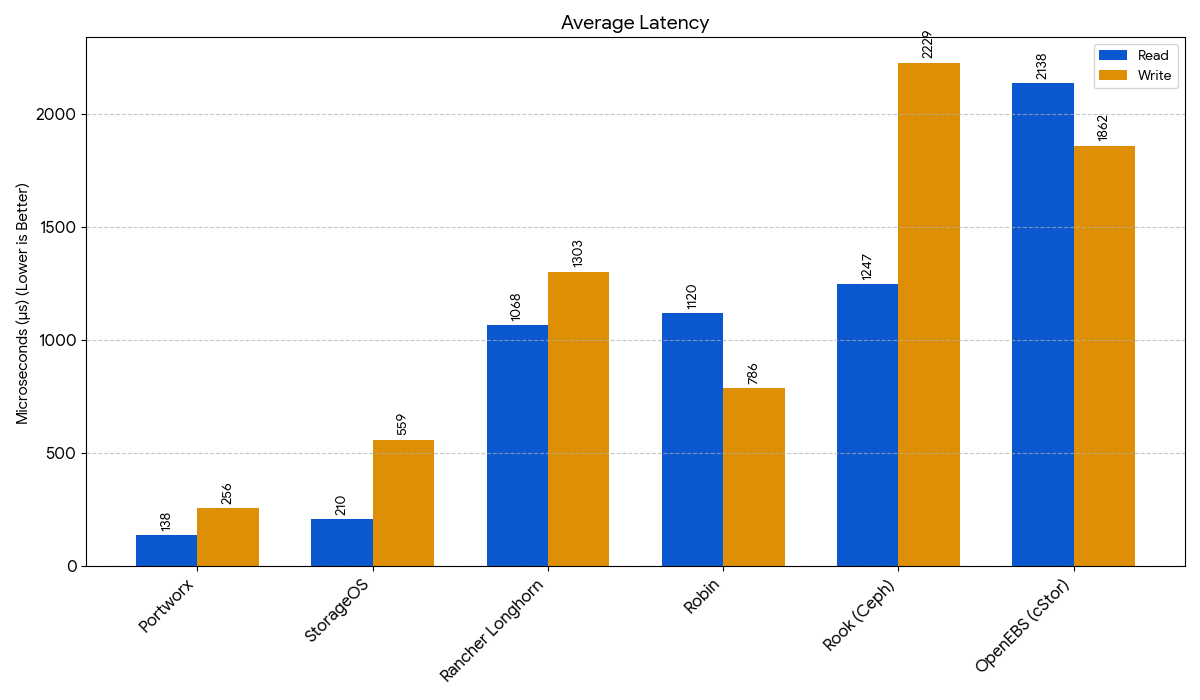
This chart illustrates the time it takes to complete a single read or write operation, measured in microseconds (µs). For latency, lower is better, as it signifies a more responsive system with less waiting time for operations to complete.
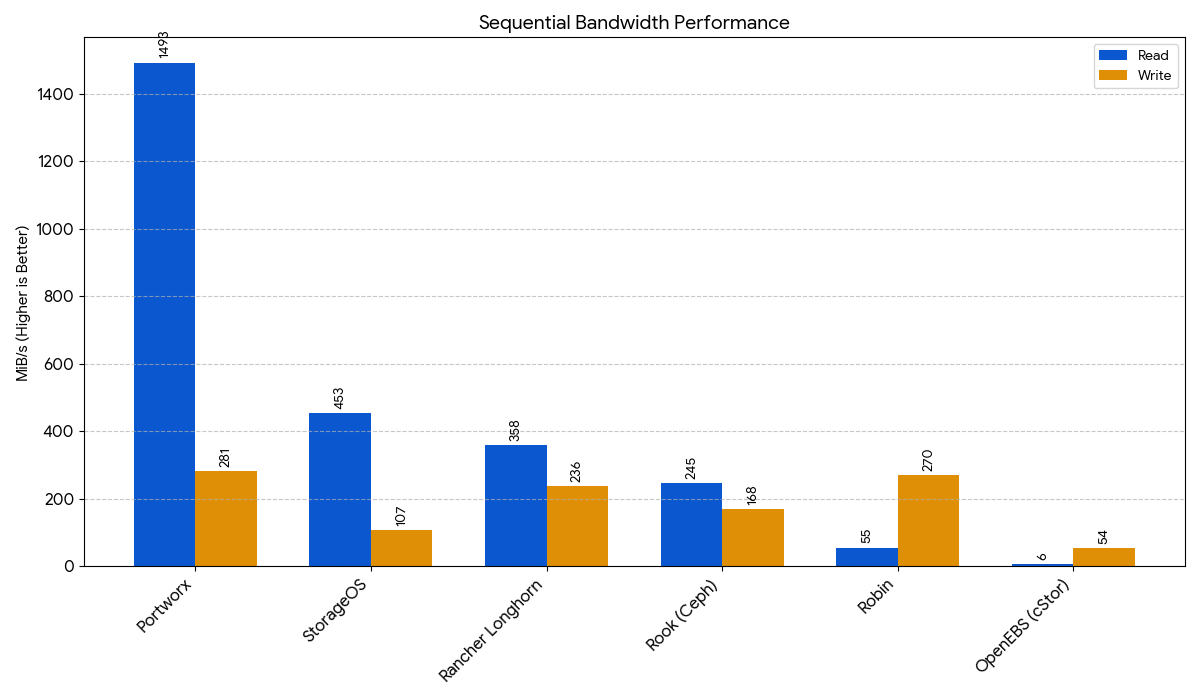
This chart shows the read and write throughput for large, sequential files, such as video streams or large backups. Higher is better, as it means large files can be read or written faster.
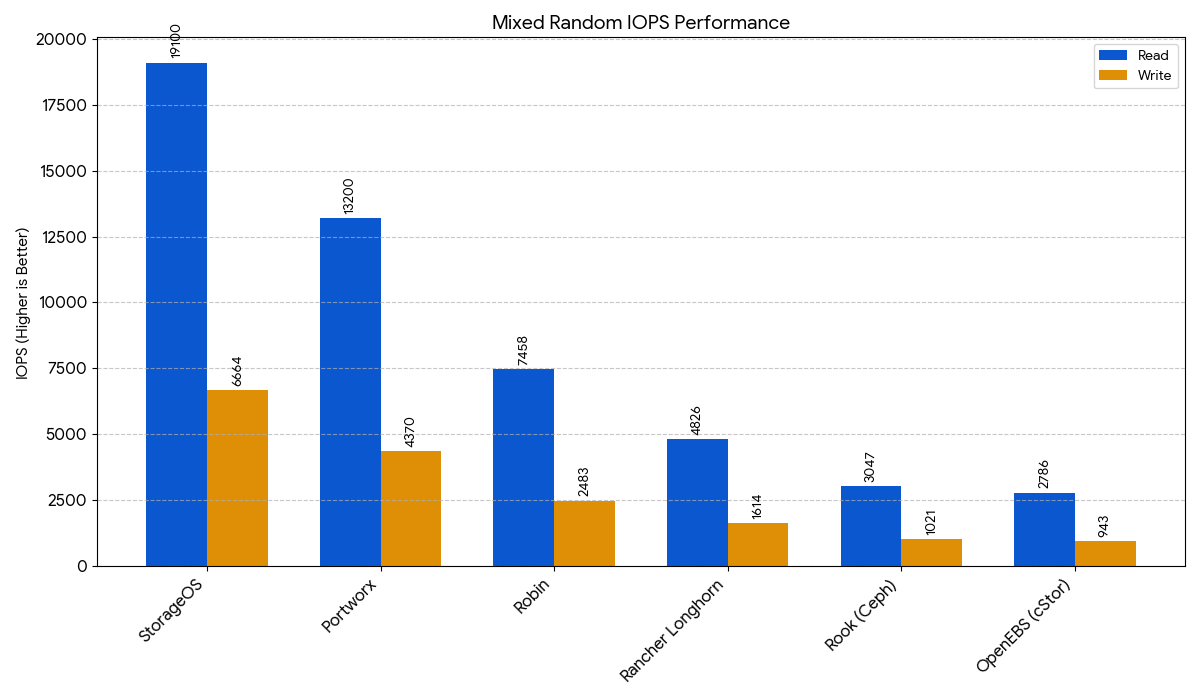
This chart measures performance in a mixed workload scenario (typically 70% read, 30% write), simulating real-world application behavior. Higher is better, indicating a stronger ability to handle complex, simultaneous demands.

Mariano Carpentier
Behrouz Hassanbeygi
Behrouz Hassanbeygi

Behrouz Hassanbeygi

Behrouz Hassanbeygi
Felix Schmitz
Address
Level 8
11-17 York Street
Sydney NSW 2000
Phone Number
+61 2 8294 8067
Email
[email protected]
By Mariano Carpentier
By Behrouz Hassanbeygi
© 2017-2026 Darumatic Pty Ltd. All Rights Reserved.


